The Hadoop stack offers a compelling set of technologies and tools that can be deployed to serve as the core of next-generation data warehouses. The combination of scalable MapReduce to analyze petabyte data sets, parallel SQL query using Hive or Impala, and data visualization tools give the analyst powerful resources for mining strategically important data. The Hadoop Distributed File System (HDFS) serves as a highly scalable data repository for hosting this data and efficiently feeding it into Hadoop’s parallel analysis engine. With industrial strength support from companies like Cloudera and others, the time is now right for deploying a Hadoop-based data warehouse:

Using ETL to Feed the Data Warehouse
A key challenge for any data warehouse is to supply data to it in a format that can be readily ingested and analyzed, and this is the role of the well-known process called “extract-transform-load” (ETL). In the case of Hadoop, this usually means extracting data from external sources and transforming them into a form that can be stored in HDFS for use by MapReduce applications. When incoming data arrives as collections of files, it’s a straightforward matter either to just copy them into HDFS or to periodically run a batch MapReduce application which reads in the files, transforms the data as needed, and outputs it to HDFS.
Consider a company that sends end-of-day reports from its field offices to the data warehouse for aggregate analysis. The data warehouse can start up a MapReduce application after the last report has been uploaded to read from an external file system, reorganize it, and then output the results to HDFS. For example, this application might use the keys output from the mappers to join data for various fields (such as, revenue, volume, etc.) across all offices so that the reducers can output this data to HDFS by field instead of by office.
Implementing ETL using MapReduce offers several advantages. It makes use of the data warehouse’s parallel infrastructure to quickly process the data on a cluster of servers. It also leverages the development team’s skill sets in developing MapReduce applications to minimize overall cost. Lastly, it avoids the need to deploy a variety of technologies, which creates unnecessary complexity and headaches for system administrators.
The Challenge: Real-Time ETL
Running ETL using a batch MapReduce job works fine for static data, such as file-based, end-of-day reports. But what about streaming data that continuously flows into the data warehouse? For example, consider an e-commerce website that accepts orders which flow to the data warehouse for analysis to identify patterns and issues. The website generates a continuous stream of orders which must be stored as HDFS files by an ETL processing step, as illustrated by the following diagram:
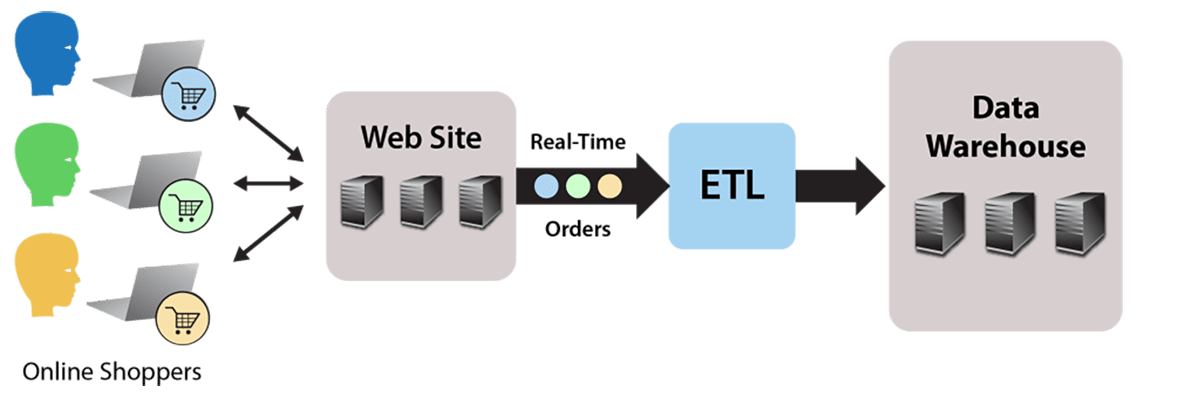
The simplest possible approach to this problem is to store the incoming orders as individual files in HDFS. Of course, this does not allow for any data translation prior to saving the files in the data warehouse. Also, this creates many file I/O operations both when loading HDFS and later when reading large numbers of small files during each analysis.
A better solution would be to run a MapReduce application that reads the input stream and outputs to HDFS. This enables the translation step to reorganize and consolidate the data as necessary and to efficiently output it to HDFS. By using standard MapReduce instead of another stream processing platform, such as Spark or Storm, the skill sets already employed for the data warehouse can be used instead of requiring a different software stack to perform ETL.
However, the data warehouse’s batch-oriented MapReduce execution environment incurs high scheduling latency (typically 15 seconds or longer) that makes it unsuitable for processing an incoming data stream. Furthermore, this MapReduce application would need to run continuously, tying up resources that were intended for data analysis, not ongoing ETL.
The Solution: Offload to an In-Memory Data Grid Running MapReduce
The streaming ETL challenge can be met by deploying an in-memory data grid with an integrated MapReduce engine, such as ScaleOut hServer, to capture the data stream in real time, perform ETL, and offload the data warehouse. Let’s take a look at how this works.
IMDGs host data in memory and distribute it across a cluster of commodity servers. Using an object-oriented data storage model, they provide APIs for storing, accessing, and updating data objects in well under a millisecond (depending on the size of the object). This enables operational systems to use IMDGs for storing fast-changing, “live” data, such as the data warehouse’s incoming order stream.
An IMDG provides an ideal repository for the data stream, buffering orders as objects within the grid and running the ETL application using built-in MapReduce (more on that below). The IMDG matches the arrival rate of the incoming data stream by adding servers as needed to its cluster, ensuring that both storage capacity and update throughput scale linearly while keeping update times fast. Also, the IMDG maintains high availability using data replication so that if a server fails, the IMDG can continue to handle update requests without delay.
Because IMDGs store data in memory distributed across a cluster of servers, they can easily perform data-parallel computations on stored data, such as the ETL function needed by the data warehouse; they simply make use of the cluster’s processing power to analyze data “in place,” that is, without the need to migrate it to other servers. This enables IMDGs to complete ETL fast (possibly in less than a second) with minimal overhead.
Some IMDGs, such as ScaleOut hServer, can execute standard Hadoop MapReduce applications (i.e., applications which are fully code-compatible with Apache Hadoop), allowing these applications to access in-memory data from the grid and output to HDFS. This enables the ETL function to be deployed as a conventional MapReduce application within the IMDG. The application extracts orders from the grid’s memory, transforms them as required for storage in the data warehouse, and then outputs them to HDFS using standard MapReduce techniques, as illustrated in the following diagram:
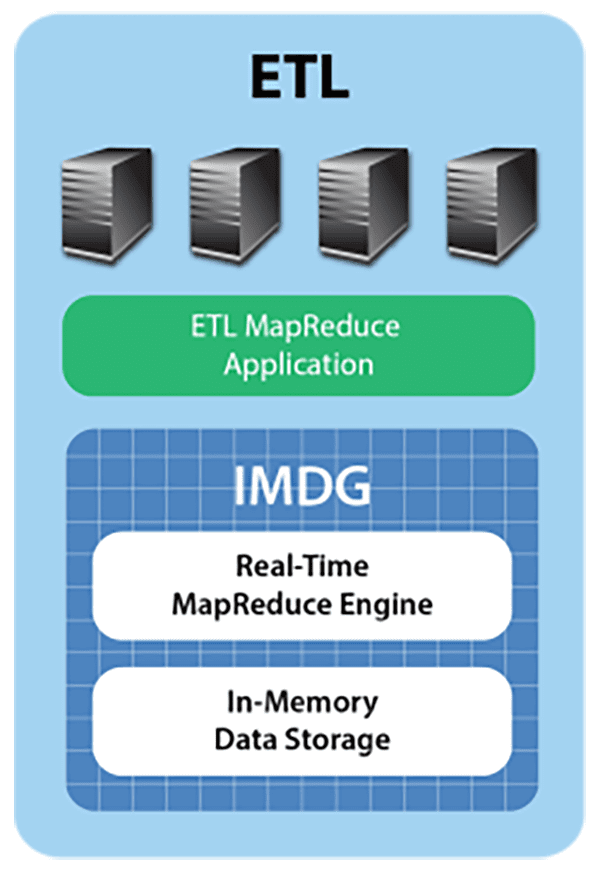
Ensuring Continuous Processing
The use of an IMDG offloads the data warehouse, allowing the MapReduce application performing ETL to run continuously. It also dramatically reduces the latency required to start up each iteration from 15+ seconds to a few milliseconds. Buffering orders in memory while simultaneously migrating them to HDFS ensures that ETL processing seamlessly keeps up with the incoming data stream.
To show how continuous processing can be achieved, the following diagram depicts the use of a “double buffering” strategy to perform ETL processing. IMDGs organize collections of objects within name spaces that can be identified and used as input to a MapReduce application. In this case, while incoming orders are added to one name space, which serves as an input buffer, the MapReduce application extracts orders from a second name space that was previously filled; it then organizes them into an appropriate format and outputs the data to HDFS. Upon completion, the extracted orders are cleared from the associated name space, the name spaces are switched, and the MapReduce application is restarted on the other name space:
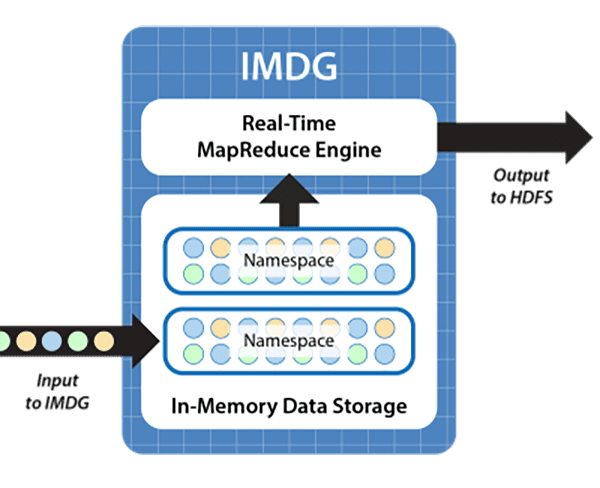
This technique uses the memory of the IMDG to allow orders to flow smoothly into the IMDG while processing by the MapReduce ETL application is ongoing. It requires that sufficient memory be available in the IMDG to buffer incoming order objects during the processing time of the application. Because the IMDG can scale memory capacity by adding servers and because the IMDG fast start-up and data-parallel execution minimize the ETL application’s processing time, continuous processing of incoming orders is ensured.
Summing Up
Hadoop’s powerful analytics capabilities are rapidly making it the centerpiece of next-generation data warehouses. The ability of IMDGs to implement ETL for streaming data enables them to serve as a vital component of these infrastructures. IMDGs which can run MapReduce applications provide the threefold benefits of meeting the low latency requirements for ingesting streaming data, offloading the data warehouse’s execution environment, and leveraging existing Hadoop skills. ETL on streaming data is yet another example of real-time analytics and a prime application for IMDGs.
Perhaps most exciting is that hosting ETL in an IMDG’s real-time analytics engine opens the door to analyzing the order stream (or a clickstream) in real time and generating instant feedback for web users. Over time, the ETL function can evolve to perform real-time analysis, provide guidance, and thereby drive incremental sales. The IMDG’s analytics engine forms a bridge from the data warehouse to customers, helping push the benefits of data analytics to the point of sale where it can have maximum impact.